
For years, the answer to “how do I rank in Google?” was a list of two hundred things nobody could realistically prioritize. Quality content. Backlinks. Page speed. User experience. Everything matters, nothing can be ignored, and the practical advice ends up being almost useless.
What changed over the last two years is not that the list became false. It is that we now have more information than ever about how the system actually works: evidence from the U.S. antitrust trial against Google, the May 2024 leak of Google’s internal API documentation with more than 14,000 Content Warehouse attributes, and two years of analysis showing which sites won and lost during the most aggressive algorithm updates in recent memory.
Audio summary
Listen to the article summary
A short version to review the main ideas before going deeper into the guide.
Free PDF
Download the companion guide
Save it so you can review the key points and apply them later.
Download PDFBefore the list: how the system works

We usually talk as if Google uses one giant algorithm, but ranking is closer to a chain of systems that evaluate each page in successive stages.
The initial system, often referred to as Mustang, makes a first selection of candidate pages based on relevance: whether the content matches the query. Then come Twiddlers, reranking functions that adjust those positions using quality signals, user behavior, freshness, and other factors. NavBoost, confirmed both in the leak and in the antitrust trial, uses click data to reorder results based on real user behavior. On top of that, filtering systems like SpamBrain and the Helpful Content system can demote pages or entire sites regardless of their other signals.
Understanding that chain matters because it changes how you think about ranking factors. There is no single switch to turn on. A page has to survive several evaluations before it reaches the position it deserves. You can have excellent content and still fail if technical signals prevent Google from reading it properly. You can have a technically clean site with content that fails the quality filter. You can pass both and still lose ground to a competitor with stronger authority on the topic.
With that frame, the ranking factors make much more sense.
SEO Bottleneck Analyzer
SEO Bottleneck Analyzer Use it to get a practical recommendation. Open tool
SEO Bottleneck Analyzer
Find which part of your SEO system is holding rankings back.
Assessment areas
Relevance: before anything else matters
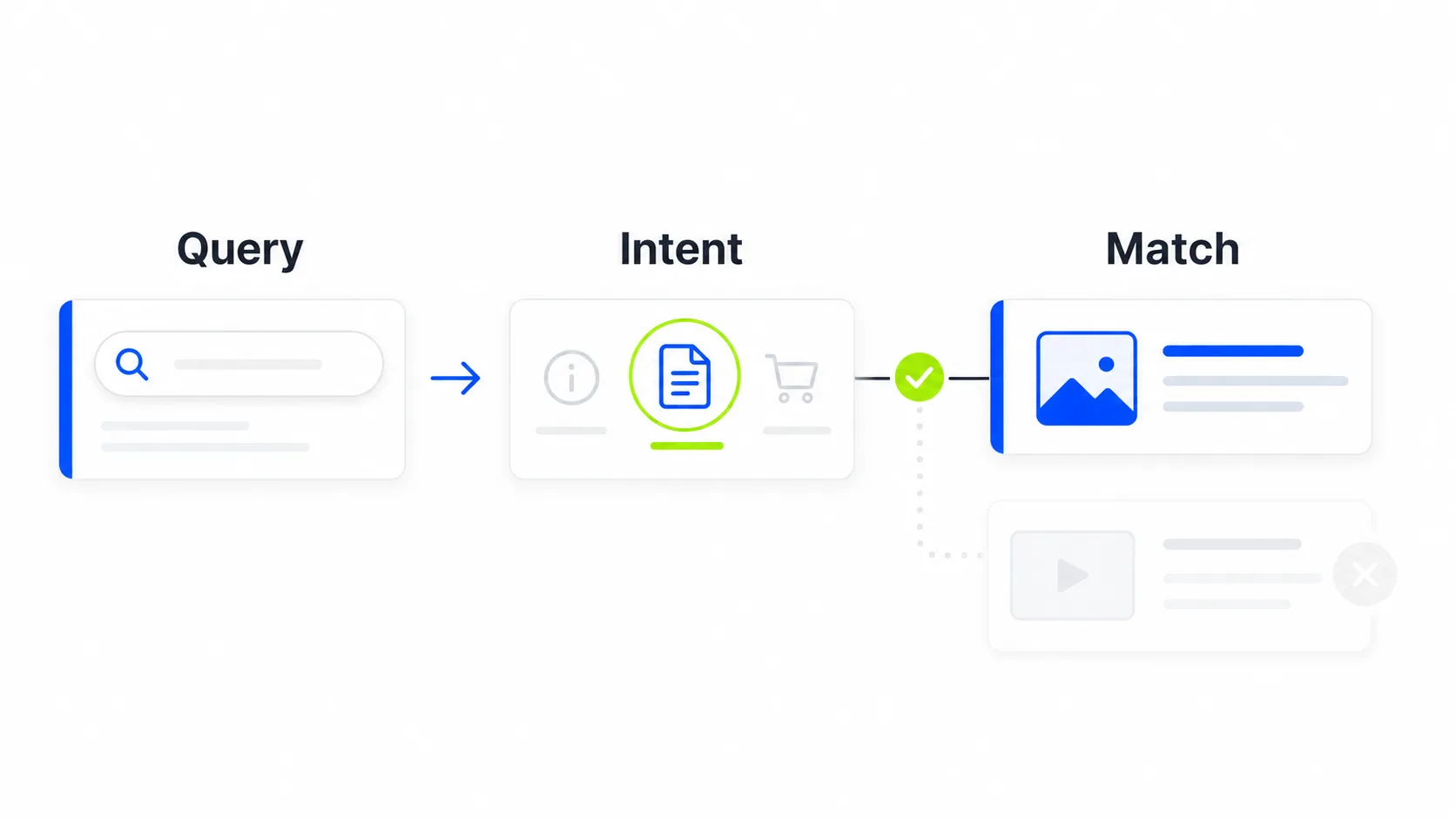
The first filter is also the most basic one: does this page answer what the user is actually looking for?
Google has spent years improving its ability to understand intent. It no longer compares isolated words; it compares meaning. RankBrain and BERT were early steps. Today’s systems go much further, evaluating whether a page satisfies the underlying intent of the query, not just whether it contains the right keywords.
That has concrete implications. A page can use the exact keyword a user searched for and still fail the relevance filter if the context is wrong. Another page can answer the question with different language and still pass if it satisfies the intent clearly and completely.
What works is analyzing what type of content ranks for the query before creating your own. If the top ten results are tool comparisons and you publish a technical tutorial, the intent does not match. Format matters as much as topic.
Content: the quality filter has a name

The 2024 leak confirmed something many SEOs suspected: Google uses an LLM to estimate the “effort” behind page content. The metric is called PageQuality, or PQ, and it considers signals such as the use of images, videos, original data, and information that cannot be found elsewhere. In practice, it is an approximation of whether the content was made for users or for the algorithm.
The documentation also confirmed the existence of OriginalContentScore, a metric that penalizes duplicated or derivative content, and ChardScore, which measures depth and usefulness in relation to the topic being covered.
In practice, content that takes the same points covered by every other article in the industry and rearranges them with different wording does not build much ChardScore or OriginalContentScore. Content that adds proprietary data, firsthand perspective, examples that do not exist in other sources, or follow-up questions other articles ignore does.
Google also measures freshness in several ways: the byline date, the date in the URL, and dates mentioned inside the content. Changing the publication date without updating the actual content does not work because the system compares historical versions.
E-E-A-T: the hardest signal to fake
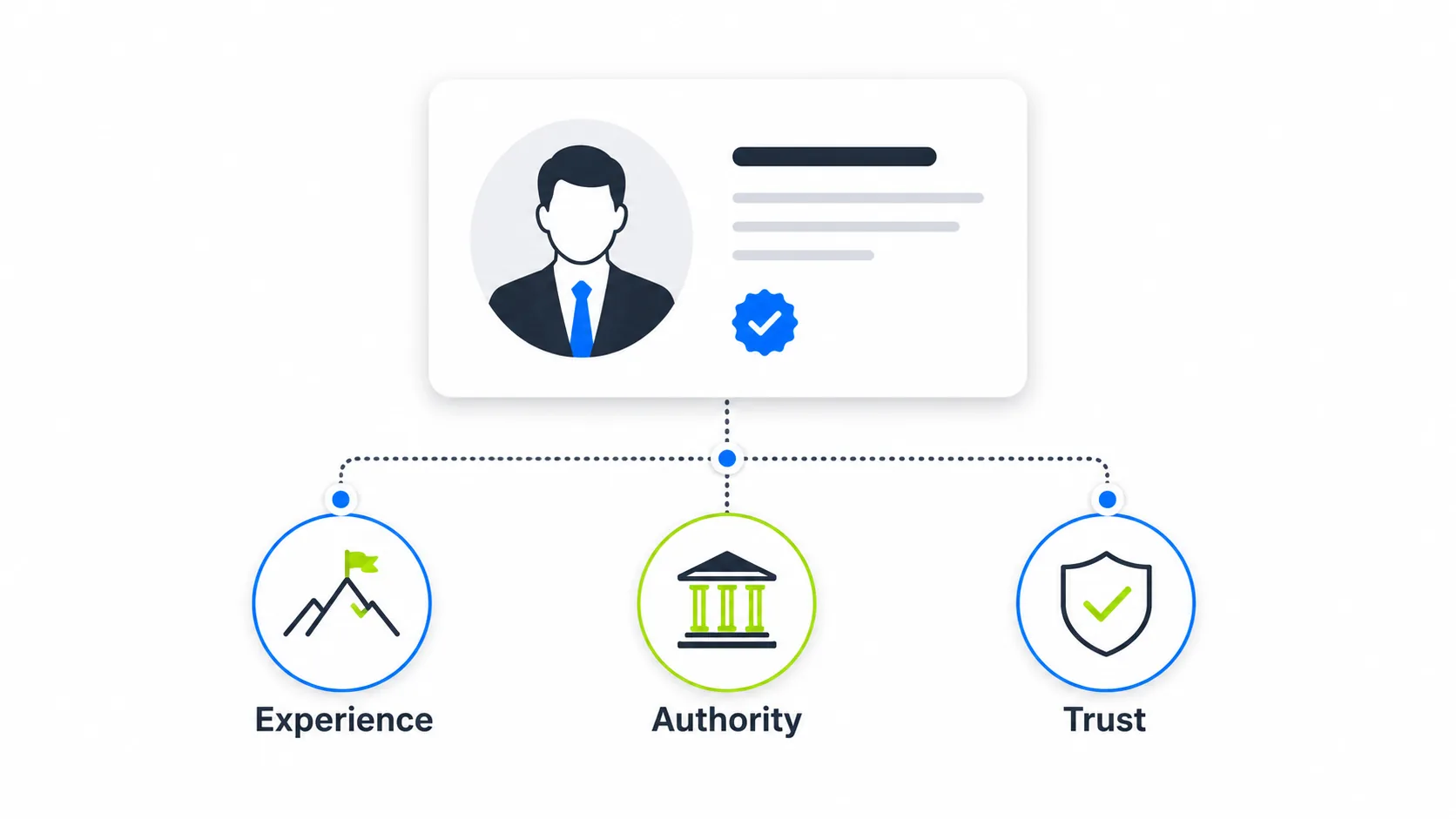
E-E-A-T, which stands for Experience, Expertise, Authoritativeness, and Trustworthiness, has been part of Google’s Search Quality Rater Guidelines for years. What the 2024 leak added is evidence of how some of that logic is implemented technically.
The leaked documents show that Google maintains databases of recognized author entities. If you write about investing and Google has mapped you as an author with publications in trusted financial media, your content receives a different authority signal than content from an author with no verifiable external presence. The metric appears in the leak as isAuthor, and SEO experts such as Lily Ray have highlighted its importance after recent core updates.
For YMYL topics, including health, finance, and safety, the scrutiny is higher. A page about medical symptoms with no identified author, no sources, and no evidence that the writer has any basis for the advice has little chance of ranking well regardless of backlinks.
What you can do: make authors visible in the content, include bios and links to profiles, cite sources with year and origin when using data, and cover topics in your area consistently over time. Topical authority is not built with one good article. It is built with a sustained pattern of coverage.
Backlinks still matter, but not like they used to
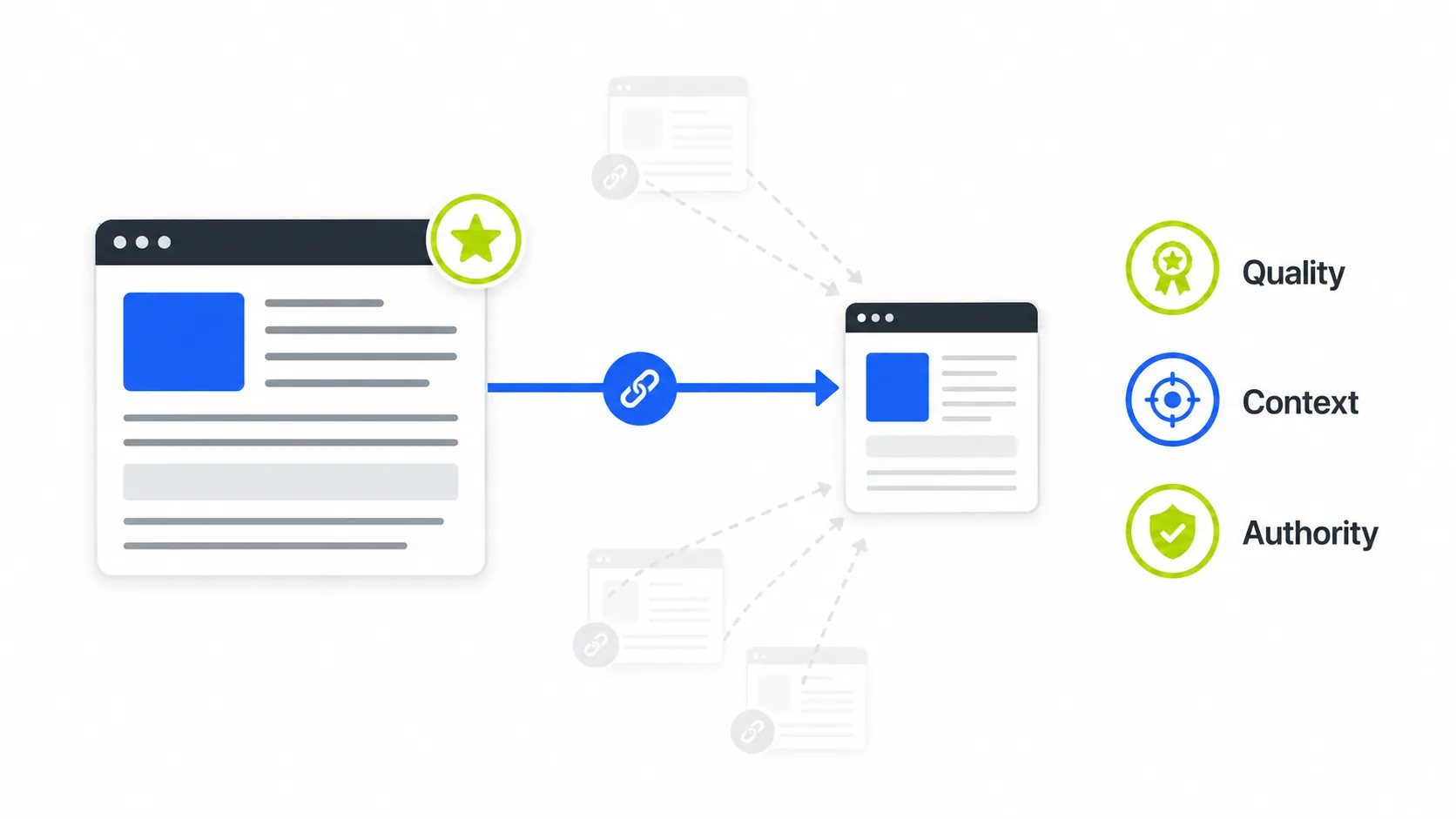
Google has said publicly several times that backlinks are less important than the SEO industry thinks. The leak contradicted part of that message.
The leaked documents confirm multiple PageRank variants, site-level authority metrics such as siteAuthority and Host NSR, and link-diversity signals. They also confirm that links from “seed sites”, high-authority reference pages, have disproportionate weight in the system, and that fresher links have a multiplier effect compared with older ones.
What changed compared with five years ago is that volume no longer compensates for quality. A backlink profile with hundreds of links from sites with no real traffic does not accumulate much signal, and in some cases can activate spam signals. What still moves the needle are contextual links from publications with real editorial traffic, co-citations alongside recognized brands in the topic, and diversity across linking domains.
After analyzing the leak, Rand Fishkin argued that the universal advice for improving rankings is to build a recognized and notable brand in your space. Strong brands accumulate branded searches, unlinked mentions, and backlinks naturally, and the system treats them differently.
User behavior: the signal Google denied for years
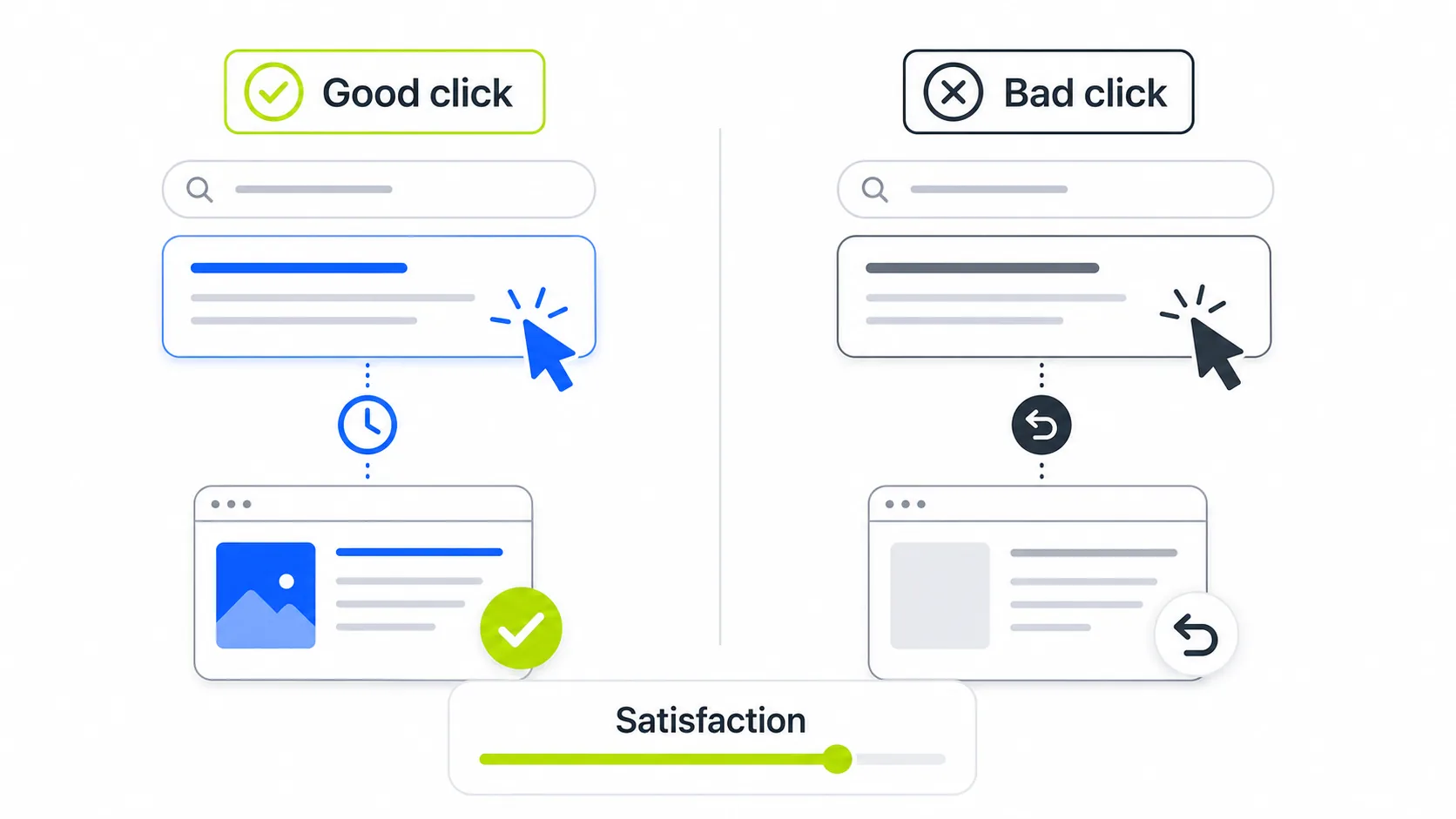
This is the most important revelation from the 2024 leak and the antitrust trial: Google uses user behavior data as a ranking signal, something its spokespeople had systematically denied for years.
NavBoost uses click data to reorder results. Metrics confirmed in the documents include goodClicks, clicks that led to a satisfying session; badClicks, clicks followed by an immediate return to the results; lastLongestClicks, the last page visited in a search session, often the page that satisfied the intent; and unsquashedClicks.
In the antitrust trial, Google executive Pandu Nayak confirmed under oath that NavBoost is “one of the important signals” in the ranking system. This is not just a theory from the leak; it was stated directly in testimony.
In practical terms: if users land on your page and immediately go back to Google to search again, that works against you. If they stay, navigate deeper into the site, or end their search journey on your page, that helps. Time on page, scroll depth, and bounce rate are not just analytics metrics. They are proxies for the quality signals the ranking system uses to adjust positions.
Tools like the Wisseo content analyzer can help detect whether your pages have the structure and depth needed to keep users once they arrive.
Technical signals: the floor, not the ceiling
Core Web Vitals, including LCP, INP, and CLS, remain confirmed ranking signals. In 2026, INP, or Interaction to Next Paint, is the metric that has gained the most weight compared with previous versions. But most sites that lose rankings against competitors do not lose because of Core Web Vitals. They lose because of differences in content, authority, or user behavior.
What can sink a site regardless of everything else are indexing problems, important pages Google cannot crawl, pages accidentally excluded from the index, architecture that prevents authority from flowing between pages, and technical spam signals such as anchor text that does not match the destination page. The leak confirmed that Google has explicit metrics for anchor mismatch and can demote pages for it.
The Wisseo SEO audit covers more than one hundred technical checks and returns a list prioritized by impact, not alphabetically. What it usually finds on sites with ranking problems is not Core Web Vitals. It is important pages blocked in robots.txt, unmanaged duplicate content, and internal linking structures that send authority toward low-value pages.
Site authority: the hardest factor to build
The leak confirmed the existence of a metric called siteAuthority, a concept Google had publicly denied under that exact name, even while acknowledging similar ideas in other language. This metric evaluates the authority of a site for specific topics, not generically.
Alongside siteAuthority, the system uses site focus and site radius: how focused a site is on a set of topics and how broad its coverage is within that space. An SEO site that covers technical SEO, link building, SEO tools, and ranking case studies has a clear site focus. One that covers SEO, recipes, personal finance, and travel does not.
This is the foundation of the topical authority concept SEOs have talked about for years. The data from recent core updates confirms it: the sites that gained visibility are the ones with coherent, deep coverage in their area. The sites that lost visibility are often those that expanded into topics unrelated to their core.
The Wisseo competitor research tool lets you see which topics higher-ranking competitors cover and how deeply they cover them. That is often more revealing than comparing backlinks.
Ranking #1 no longer guarantees AI citations
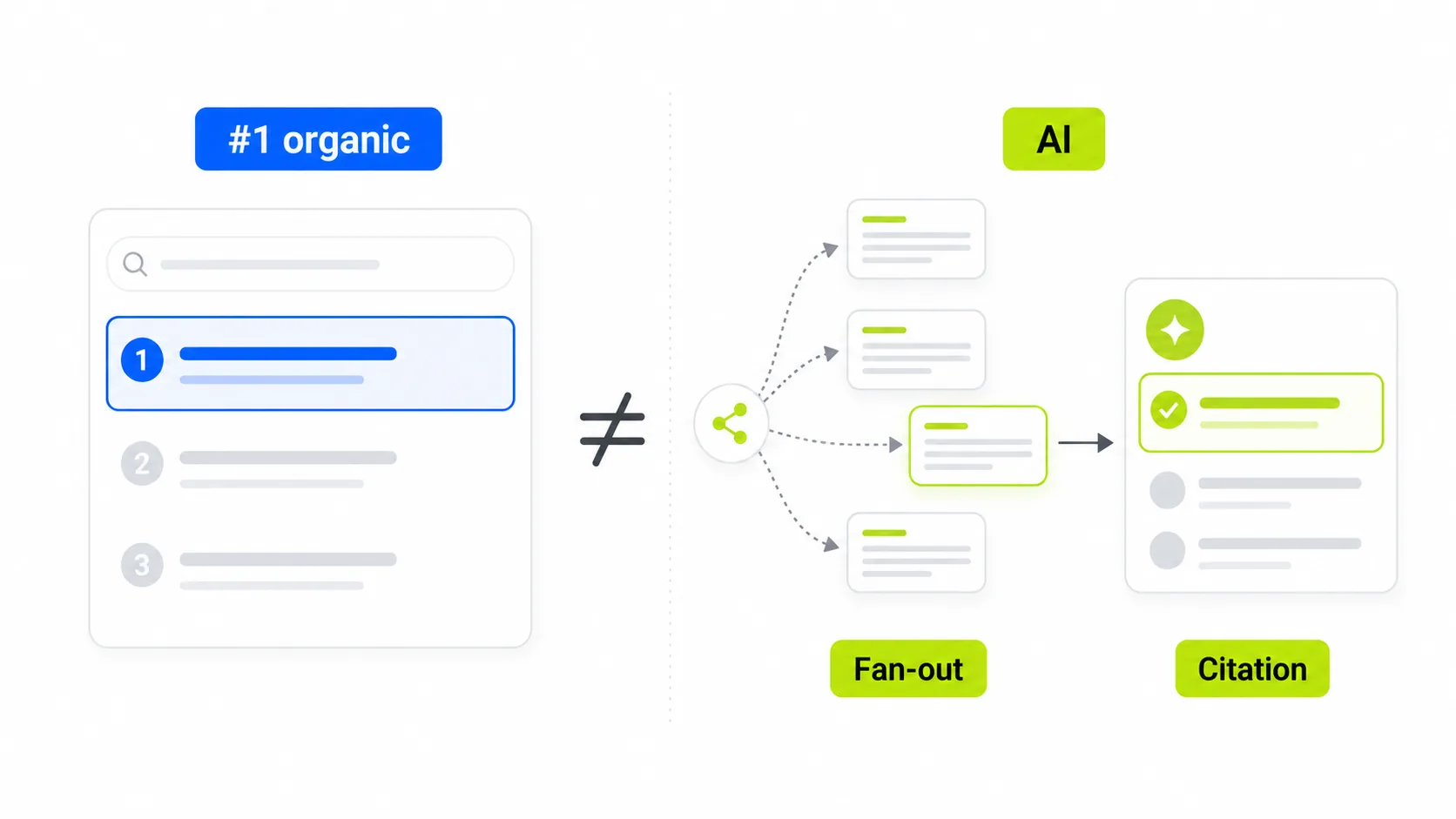
In July 2025, 76% of pages cited in Google AI Overviews also appeared in the organic top 10 for the same query. By early 2026, that percentage had fallen to between 17% and 38%, depending on the study. Ahrefs’ analysis of 863,000 SERPs and 4 million AI Overview URLs confirmed the point: only 38% of cited pages ranked in the top 10 for the same query. Thirty-one percent did not appear in the top 100 at all.
The mechanism behind that shift has a name: query fan-out. When someone searches and AI Mode or AI Overviews activates, Gemini does not simply search for the answer to that exact query. It breaks the query into 8 to 12 related sub-queries, runs them in parallel, and synthesizes an answer by citing pages that appear consistently across the largest number of those sub-queries. A page that ranks for the main query but not for any sub-query has a much lower chance of being cited than a page that appears across eight of them, even if it is not in the top 10 for the main result.
A Surfer SEO analysis of 173,902 URLs found a Spearman correlation of 0.77 between fan-out query coverage and AI Overview citations. Pages that rank for fan-out queries are 161% more likely to be cited. The data is strong enough to change how we think about content architecture.
The practical implication is direct: a pillar page that covers a topic in depth from several angles is more likely to be cited in AI than ten thin pages, each optimized for a different keyword. You are no longer optimizing for one term. You are optimizing for the set of questions a user might ask about the topic.
If you sell online, there is a technical problem you probably do not know you have
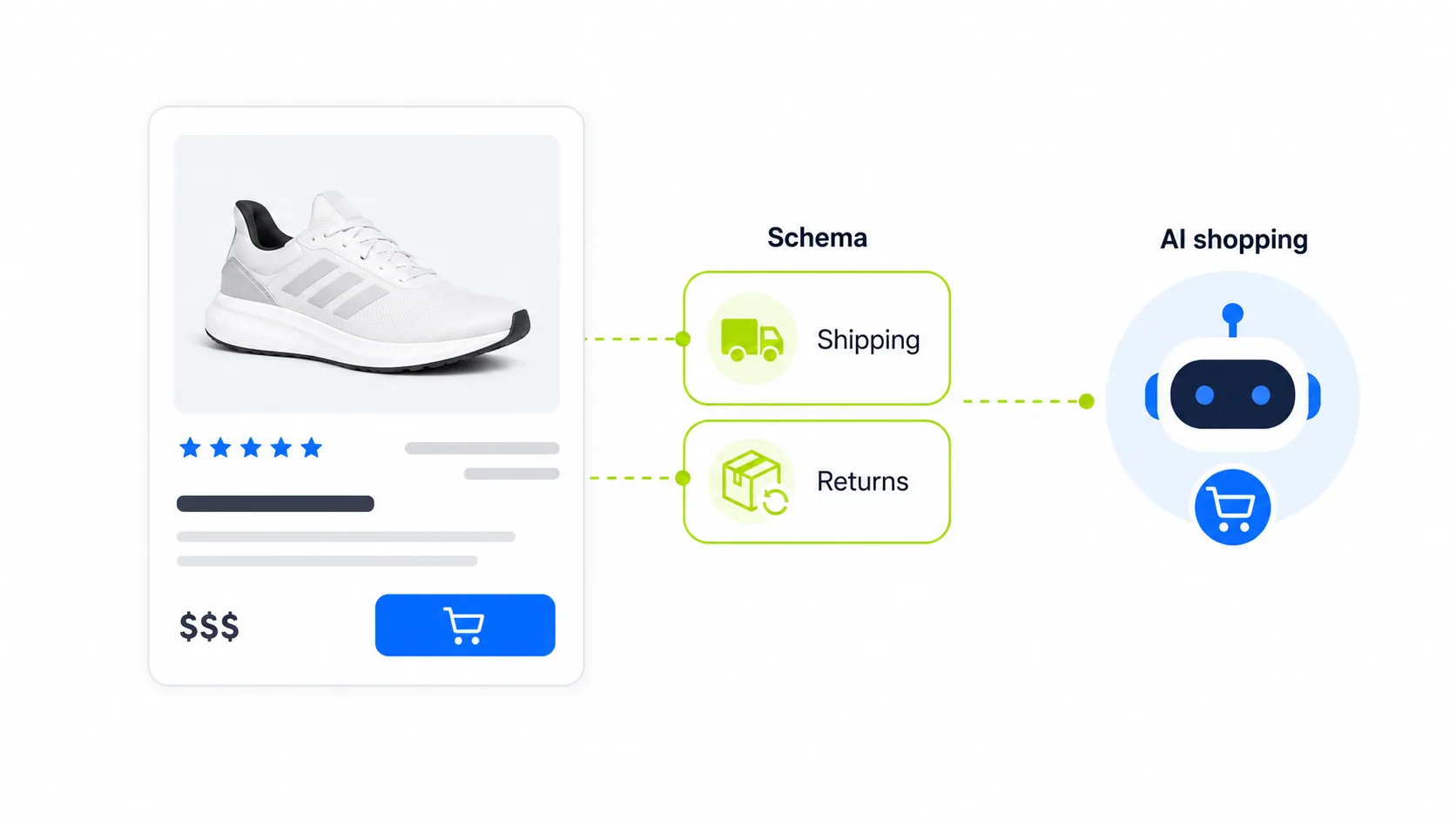
Since January 2026, AI shopping agents need to know two things before recommending a product: how much shipping costs and under what conditions the product can be returned. If your product page does not include that information in machine-readable format, the agent cannot calculate the total cost of the purchase or guarantee return conditions. And if it cannot guarantee them, it will not recommend the product.
Google and the major LLMs have made MerchantReturnPolicy and OfferShippingDetails objects mandatory inside product schema. Missing this data makes the product invisible to AI shopping agents.
This is not a theoretical warning. In Google Search Console, the error “Missing field ‘hasMerchantReturnPolicy’ (in ‘offers’)” now appears for many stores that have not implemented it. For years it was a non-critical warning. In 2026, it determines whether an agent can include your product in a comparison.
The schema you need on each product page includes the accepted return type, the return window in days, the return method, and whether return shipping is free or paid. For shipping, it requires the cost, destination, and estimated delivery time. All of it should be in JSON-LD, nested inside the product’s Offer object.
Shopify also recommends mapping each product variant with GTIN and MPN identifiers, because AI systems use those codes to group products and compare prices across stores. A product without a GTIN is harder for an agent to identify unambiguously when comparing several sellers.
The Wisseo schema generator includes Product, Offer, MerchantReturnPolicy, and OfferShippingDetails types and generates JSON-LD ready to implement without writing code manually.
What no longer moves the needle

There are things the SEO industry has kept doing out of inertia even though the current understanding of Google’s algorithm suggests they have little or no impact.
Keyword density stopped being relevant a long time ago. Google understands context and meaning, not term frequency. Content that repeats its target keyword twenty times does not rank better than content that uses it three times but answers the question more precisely.
Having the keyword in the domain does not give a meaningful advantage either. The leak did not reveal metrics that prioritize a match between the domain and the query. What the system measures is the authority and relevance of the site’s content, not its URL.
Metadata in isolation does not rank pages. The title tag and meta description are relevance signals Google considers, but optimizing them without solving the underlying problem, content that does not satisfy intent or insufficient authority on the topic, will not move much.
And backlinks from sites with no real traffic, even if they are dofollow and have a reasonable DR, contribute little. The leak suggests the system weights links partly based on the real traffic of the linking site, not only its backlink profile.
The conclusion you did not want to read

Ranking factors in 2026 are not a checklist. They are a system. And that system rewards basically the same things any serious publication rewards: content that is genuinely good, written by people who know what they are talking about, referenced by relevant sites, and satisfying for users who arrive from search.
What changed is that we now know much more precisely how those things are measured. And that does change the work: not toward more tricks, but toward fewer.

